Yerel olarak yapay zeka çalıştırıyorsanız, muhtemelen şu tavsiyeyi duymuşsunuzdur: “İyi bir GPU alın.” Peki bu aslında ne anlama geliyor? Ve CPU’nuz gerçekten o kadar işe yaramaz mı? Cevap, “GPU iyi, CPU kötü” kadar basit değil. Önemli olan, her bir işlemcinin yapay zeka çıkarımının arkasındaki matematiksel işlemleri nasıl işlediği ve hangisinin bu hızı yakalayabilecek kadar hızlı veri aktarımı yapabildiğidir.
AI çıkarım sürecinde gerçekte neler oluyor?
Yerel bir LLM veya görüntü modelini çalıştırdığınızda, donanımınız tek bir işlemi tekrar tekrar gerçekleştirir: matris çarpımı. Model, girdi verilerinizi alır, bunları sayılara dönüştürür ve bu sayıları katmanları boyunca milyarlarca matematiksel işlemden geçirir. Donanımınız bu işlemleri ne kadar hızlı gerçekleştirebilirse, yanıtı da o kadar çabuk alırsınız.
Bu, eğitilmiş bir modelden çıktı elde etme işlemi olan çıkarımdır. Burada herhangi bir şeyi eğitmiyorsunuz. Sadece hesaplamaları tek tek, her seferinde bir token üzerinde gerçekleştiriyorsunuz.
Bir CPU Yapay Zeka İşlemlerini Nasıl Yürütür?
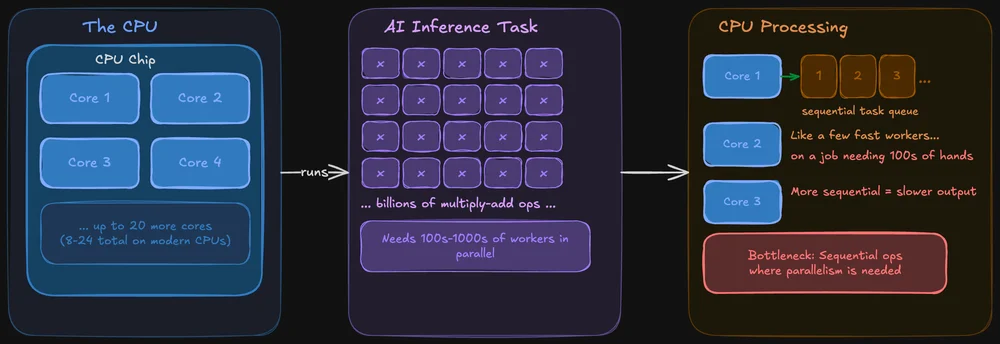
Bir CPU, her konuda başarılı olacak şekilde tasarlanmıştır. İşletim sisteminizi, tarayıcı sekmelerinizi ve dosya sisteminizi yönetir; evet, yapay zeka modellerini de çalıştırabilir. Modern CPU’lar çok sayıda çekirdeğe sahiptir (tüketiciye yönelik yongalarda genellikle 8–24 adet) ve her bir çekirdek hem güçlü hem de esnektir.
Sorun şu: Yapay zeka çıkarımında, aynı işlem devasa miktarda veri üzerinde aynı anda gerçekleştirilir. Bir CPU bunu yapabilir, ancak bu işlemleri daha çok sıralı bir şekilde işler. Bu durum, aslında aynı anda yüzlerce kişinin çalışması gereken bir işi, birkaç çok hızlı işçinin üstlenmesine benziyor.
Bununla birlikte, CPU'lar yerel yapay zeka uygulamaları için tamamen elverişsiz değildir. llama.cpp gibi araçlar, CPU üzerinde çıkarım yapmak üzere özel olarak optimize edilmiştir; modeliniz sistem RAM'ine sığıyorsa, onu kesinlikle sadece CPU üzerinde çalıştırabilirsiniz. Modelin boyutuna bağlı olarak, bazen fark edilebilir derecede, bazen de fark edilmeyecek kadar yavaş olacaktır.
Bir GPU Yapay Zeka İşlemlerini Nasıl Yürütür?
GPU, paralellik ilkesi üzerine tasarlanmıştır. Bir CPU’da 8 ila 24 çekirdek bulunurken, modern bir GPU’da aynı problemin farklı bölümlerini aynı anda işleyebilen binlerce küçük çekirdek bulunur. Bu özellik, GPU’ları yapay zeka modellerinin dayandığı türden toplu hesaplamalarda olağanüstü derecede başarılı kılar.
Bunun yanı sıra, GPU'lar sistem RAM'inden çok daha yüksek bant genişliğine sahip kendi özel belleklerine (VRAM) sahiptir. Bu bant genişliği, verilerin o binlerce çekirdeğe ne kadar hızlı aktarılabileceğini belirlediği için büyük önem taşır. Daha fazla bant genişliği, daha az bekleme süresi ve daha fazla hesaplama süresi anlamına gelir.
Özellikle yerel LLM çıkarımında GPU'nun sağladığı avantaj iki unsura dayanır: paralel işleme gücü ve bellek bant genişliği. Her ikisi de çıktınızda saniyede kaç token göreceğinizi doğrudan etkiler.
Bellek Bant Genişliği
Çoğu insanı şaşırtan bir gerçek şudur: Yerel LLM çıkarımında, sınırlayıcı faktör genellikle ham hesaplama gücü değildir. Asıl sınırlayıcı faktör bellek bant genişliğidir.
Tahmin aşamasında, üretilen her bir token için model ağırlıklarının bellekten okunması gerekir. Belleğiniz işlemciye verileri yeterince hızlı aktaramazsa, kaç çekirdeğiniz olduğu fark etmez; çekirdekler sadece orada beklemek zorunda kalır.
İşte bu yüzden VRAM bant genişliği bu kadar önemli. Tipik bir DDR5 sistem belleği kurulumu 50–90 GB/s bant genişliği sunabilir. RTX 5090 gibi modern bir GPU ise 1.000 GB/s'nin üzerinde bant genişliği sunar. Bu, on katlık bir fark demektir.
Modeliniz tamamen VRAM'e sığıyorsa, sırf bu nedenle bile çıkarım işlemi GPU'da CPU'ya göre neredeyse her zaman daha hızlı olacaktır.
Sadece CPU Kullanımı Ne Zaman Mantıklıdır?
GPU her zaman çözüm değildir. CPU üzerinde çalıştırmanın doğru seçim olduğu gerçek senaryolar vardır:
- Hız farkının neredeyse hiç fark edilmediği küçük bir model (3B parametre veya daha az) çalıştırıyorsunuz.
- Uyumlu bir grafik kartınız yok ya da grafik kartınızda modeli çalıştırmaya yetecek kadar VRAM yok.
- Daha büyük bir modeli daha düşük hızda çalıştırmak için sistem RAM'inizin tamamını (ki bu genellikle VRAM'den çok daha fazladır) kullanmak istiyorsunuz.
- GPU'nun güç tüketimi veya ısınması sorun teşkil eden bir dizüstü bilgisayar veya sistem kullanıyorsunuz.
Kuantizasyon (daha az bellek kullanmak için model hassasiyetini düşürme) ve bu amaçla optimize edilmiş çerçeveler sayesinde CPU üzerinde yapılan çıkarım işlemleri önemli ölçüde iyileşti. 32 GB RAM’e sahip modern bir CPU üzerinde çalışan kuantize edilmiş 7 milyar boyutlu bir model, birçok görev için yeterince iyi performans gösteriyor.


Peki ya yük devretme?
Modeliniz VRAM kapasitesini aşıyor ancak yine de GPU hızlandırmasından yararlanmak istiyorsanız, çoğu yerel LLM aracı kısmi yük devretmeyi destekler. Bu, modelin bazı katmanlarının GPU üzerinde, geri kalanının ise CPU üzerinde çalıştırıldığı anlamına gelir.
Bu bir ödünleşmedir: GPU hızından bir miktar fayda sağlarsınız, ancak CPU'ya bağlı katmanlar bir darboğaz haline gelir. VRAM'e ne kadar çok katman sığdırabilirseniz, o kadar hızlı olur. Ve eğer GPU'ya sadece birkaç katman sığarsa, verileri ileri geri aktarmaktan kaynaklanan ek yük, bunu tamamen CPU ile yapılan çıkarımdan daha yavaş hale getirebilir.
Genel kural şudur: Modelin en az yarısını VRAM’e sığdıramıyorsanız, onu tamamen CPU üzerinde çalıştırıp kendinizi bu karmaşıklıktan kurtarmanız daha iyi olur.
Yerel Yapay Zeka Alanında NVIDIA ve AMD
NVIDIA, şu anda yerel yapay zeka alanında hakim konumda; bunun başlıca nedeni ise CUDA. Neredeyse tüm yapay zeka araçlarının üzerine inşa edildiği, NVIDIA’ya ait özel hesaplama çerçevesi. Windows üzerinde LM Studio, Ollama veya llama.cpp kullanıyorsanız, NVIDIA GPU’ları size en sorunsuz deneyimi ve en az sorunla karşılaşma olasılığını sunacaktır.
AMD arayı kapatıyor. ROCm (AMD’nin CUDA’ya cevabı) önemli ilerlemeler kaydetti ve Ollama gibi araçlar, Windows üzerinde AMD Radeon GPU’ları açıkça destekliyor. Ancak ekosistem hâlâ daha sınırlı ve kullandığınız GPU’ya ve araca bağlı olarak uyumluluk sorunlarıyla karşılaşabilirsiniz.
Özellikle yerel yapay zeka uygulamaları için bir ürün satın alıyorsanız, şu anda NVIDIA daha güvenli bir seçimdir. Zaten bir AMD GPU'nuz varsa, kesinlikle denemeye değer; ancak önce kullandığınız aracın belgelerine bakarak desteklenen modelleri kontrol edin.

CORSAIR AI300'ün Uygun Olduğu Yerler
İster yetersiz VRAM, ister düşük bellek bant genişliği, ister 13B modelini yüklediğiniz anda aşırı ısınan bir sistem olsun, mevcut kurulumunuzda bir darboğaz yaşıyorsanız, CORSAIR AI Workstation 300 (AI300) tam da bu tür sorunları çözmek için tasarlanmıştır.
AI300, yerel AI çıkarımının gerçeklerine göre tasarlanmış kompakt bir iş istasyonudur:
- Daha büyük modeller ve daha geniş bağlam pencereleri için yeterli alana sahip yüksek bellekli yapılandırma.
- Yapay zeka iş yükleri (ve biraz da oyun) için ölçeklenebilir şekilde tasarlanmış grafik belleği.
- Donanım düzeyinde bir performans seçici (Sessiz / Dengeli / Maksimum) sayesinde, gerektiğinde hıza, gerekmediğinde ise sessizliğe öncelik verebilirsiniz.
- CORSAIR AI Yazılım Paketi, kurulum sürecini basitleştirerek yapılandırmaya daha az, modelleri çalıştırmaya ise daha fazla zaman ayırmanızı sağlar.
Eğer bu amaçla tasarlanmamış bir sistemden yerel yapay zeka çözümleri elde etmeye çalışıyorsanız, AI300 size donanım ve yazılımın iş yüküne göre özel olarak tasarlanmış bir makine sunar.

MAKALEDEKI ÜRÜNLER
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.