Bir LLM modelini yerel olarak çalıştırmak, modelin bilgisayarınızda barındırılması ve komut satırlarınızın (ve modele aktardığınız tüm dosyaların) makinenizden dışarı çıkmasına gerek kalmaması anlamına gelir. Bulut hesabı yok. API anahtarları yok. “Verilerinizle model eğiteceğiz… muhtemelen… belki” gibi sözler yok. Sadece siz, bilgisayarınız ve ona verdiğiniz her görevi yerine getiren bir model.
“Yerel LLM” tam olarak nedir?
Yerel bir LLM, uzak bir sunucu yerine bilgisayarınızda çalışan büyük bir dil modelidir. Pratikte bu, genellikle model dosyalarını indirip bunları yerel bir uygulamaya yüklediğiniz ve bir bulut asistanıyla sohbet eder gibi bu modellerle sohbet ettiğiniz anlamına gelir; tek fark, “sunucu”nun sizin bilgisayarınız olmasıdır.
Bir LLM'yi yerel olarak "çalıştırmak", neredeyse her zaman çıkarım yapmak (yanıtlar üretmek) anlamına gelir; sıfırdan yepyeni bir model eğitmek değil.
Neden yerel bir LLM çalıştırmalı?
İnsanların bulut tabanlı büyük dil modellerinden yerel modellere geçmelerinin birkaç nedeni vardır:
- Gizlilik: Komutlarınız cihazda kalır (bulut bağlayıcıları kullanmadığınız sürece).
- Çevrimdışı kullanım: Model indirildikten sonra internet bağlantısı olmadan çalıştırabilirsiniz.
- Kullanım sınırı yok: Hız sınırlaması yok, “bugünkü kotanızı aştınız” uyarısı yok, sürpriz faturalar yok.
- Kontrol: İstediğiniz modeli seçin; herhangi bir abonelik modeline bağlı değilsiniz.
Elbette, rahatlığı kontrol karşılığında feda ediyorsunuz. Bulut modeli sihir gibi gelebilir; yerel model ise donanımınıza bağlı olarak sihir gibi gelebilir.
Yerel bir LLM'yi çalıştırmak için nelere ihtiyacınız var?
Kısaca: CPU işini yapıyor, GPU yardımcı oluyor, bellek önemli.
İşte eğlenceli vakit geçirip geçirmeyeceğinizi belirleyen asıl faktörler şunlardır:
- RAM / VRAM: Daha büyük modeller daha fazla bellek gerektirir. Bellek yetersiz kalırsa model çalışmaz.
- Depolama: Modellerin boyutu büyük olabilir. Bazı kütüphaneler, indirdiğiniz modele bağlı olarak model depolama alanının onlarca ila yüzlerce GB'a ulaşabileceği konusunda uyarıda bulunur.
- GPU: Uygulamanız GPU'nuzu destekliyorsa, genellikle önemli ölçüde bir hız artışı göreceksiniz.
32 GB veya daha fazla RAM'e sahip modern bir Windows 10/11 bilgisayarı, daha küçük yerel modeller için sağlam bir temel oluşturur; daha fazla bellek ise daha büyük modelleri daha rahat bir şekilde çalıştırmanıza olanak tanır.
Bir “yerel LLM çalıştırıcı” uygulaması seçin
LM Studio (kullanımı kolay grafik kullanıcı arayüzü)
LM Studio, modelleri indirip onlarla yerel olarak sohbet etmenizi sağlayan bir masaüstü uygulamasıdır. Ayrıca geliştiriciler için programlanabilir bir yerel API de içerir.
Ollama (basit komut satırı arayüzü + yerel API)
Ollama, yerel bir Windows uygulaması olarak çalışır ve size bir komut satırı iş akışı ile yerel bir HTTP API uç noktası sunar. Windows üzerinde NVIDIA ve AMD Radeon GPU'larını açıkça destekler.
llama.cpp (meraklılar için)
Maksimum kontrol istiyorsanız, llama.cpp, derleme talimatları ve çeşitli arka uç seçenekleri sunan popüler bir açık kaynaklı çıkarım motorudur.

İlk modelinizi kurun ve çalıştırın
Daha büyük modeller daha fazla RAM ve/veya VRAM gerektirir. Yeterli belleğiniz yoksa, performans düşüşü, sistem çökmeleri ya da sürekli diske yazma işlemleri (sanki bilgisayarınız balçık içindeymiş gibi hissettiren) ile karşılaşırsınız.
int4 kuantize edilmiş modeller için güvenilir bir genel kural:
- 8 GB RAM → ~3B modeller
- 16 GB RAM → ~7 milyar model
- 32 GB RAM → ~13 milyar model
Ve eğer GPU hızlandırmasından yararlanıyorsanız:
- 6 GB VRAM → ~3 milyar model
- 8 GB VRAM → ~7 milyar model
- 12 GB VRAM → ~13 milyar model
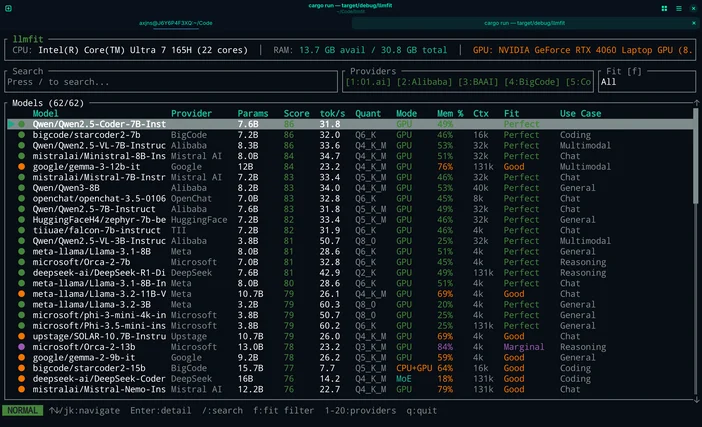
Ya da tahmin etmek istemiyorsanız, LLMfit'i kullanarak modelleri donanımınızın özelliklerine tam olarak uyarlayabilirsiniz.
LLMfit, CPU, RAM ve GPU/VRAM bilgilerinizi algılayan bir terminal aracıdır. Ardından modelleri uygunluk, beklenen hız, bağlam ve kalite kriterlerine göre sıralar ; böyleceherhangi bir şey indirmeden önce hangilerinin sorunsuz çalışacağını görebilirsiniz.
Ne için kullanılır:
- RAM/VRAM sınırlarınıza gerçekten uyan modelleri bulmak
- Önerilen nicelemeyi görme (böylece belleği aşırı yüklememiş olursunuz)
- Kıyamet senaryoları içeren model merkezleri yerine, sıralamalı bir aday listesi elde etmek
Bu iş akışında nasıl kullanılır:
- Sistem donanımınızı taramak için llmfit komutunu çalıştırın
- En üstteki “uygun sonuçlar” / önerilere bakın
- Makinenize uygun bir model boyutu seçin, ardından LM Studio / Ollama / llama'dan indirin
Her şey hazır!
Hepsi bu kadar. Bir çalıştırıcı seçin, donanımınıza uygun bir model indirin ve komut vermeye başlayın! Her şey bilgisayarınızda kalır. Bilgisayar mühendisliği diplomasına, bulut aboneliğine ya da sorun gidermekle geçireceğiniz bir hafta sonuna ihtiyacınız yok. Tüm süreç, bir oyun yüklemek kadar sürer. Ve bir kez çalışmaya başladığında, kendi şartlarınıza göre çalışan özel, çevrimdışı bir yapay zeka asistanına sahip olursunuz.
CORSAIR AI300'ün Uygun Olduğu Yerler
Windows üzerinde yerel LLM'leri çalıştırmayı ciddiye alıyorsanız, özellikle de daha büyük modeller, daha geniş bağlam pencereleri veya daha akıcı bir performans istiyorsanız, işte tam da bu noktada CORSAIR AI Workstation 300 (AI300) ve CORSAIR AI Yazılım Paketi size bir sonraki seviyeye ulaşmanızda yardımcı olur.
Yerel çıkarım işlemlerinde genellikle bellek ve veri işleme kapasitesi darboğazları yaşanır. AI300, bu gerçeği göz önünde bulundurarak tasarlanmıştır:
- Yerel yapay zeka iş akışları için tasarlanmış kompakt bir iş istasyonu
- Daha büyük modeller için rahatlık sağlayan yüksek bellekli yapılandırma
- Yapay zeka kullanım senaryolarına göre ölçeklendirilmesi amaçlanan grafik belleği davranışı
- Donanım düzeyinde bir performans seçici (Sessiz / Dengeli / Maksimum) sayesinde sessizliği mi yoksa hızı mı tercih edeceğinize karar verebilirsiniz

Windows'ta yerel bir LLM çalıştırmak için NVIDIA GPU'ya ihtiyacım var mı?
Hayır. Bazı araçlar Windows üzerinde AMD’yi açıkça desteklemektedir; örneğin, Ollama’nın Windows belgelerinde hem NVIDIA hem de AMD Radeon GPU desteği belirtilmiştir.
Yerel bir LLM'yi tamamen çevrimdışı olarak çalıştırabilir miyim?
Evet, uygulamayı ve model dosyalarını indirdikten sonra. İlk kurulumlar ve model indirmeleri genellikle internet bağlantısı gerektirir, ancak her şey yerel olarak yüklendikten sonra çıkarım işlemi çevrimdışı olarak gerçekleştirilebilir.
Yerel yapay zeka otomatik olarak gizli mi?
Öyle olabilir, ancak bu kurulumunuza bağlıdır. Yerel çıkarım, modelin cihazınızda çalıştığı anlamına gelir; ancak bazı uygulamalar isteğe bağlı bulut bağlantıları sunar. Amacınız “bulut gerektirmeyen” bir sistemse, bulut entegrasyonlarını devre dışı bırakın ve yalnızca yerel modelleri kullanın.
Yerel modelim neden yavaş çalışıyor?
Genellikle şunlardan biri:
- Model, mevcut RAM/VRAM kapasiteniz için çok büyük
- GPU hızlandırma mevcutken sadece CPU kullanıyorsunuz
- Yüksek bir bağlam uzunluğu seçtiniz ve bu, belleği tüketiyor
- Depolama alanınız doldu (evet, bu önemli)
MAKALEDEKI ÜRÜNLER
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.