Kendi bilgisayarınızda büyük bir dil modeli (LLM) çalıştırmak kulağa zor gelebilir, ancak şaşırtıcı derecede kolaydır. "Yerel LLM", yapay zekanın bulut veya hesap olmadan donanımınızda çalıştığı ve verilerinizin sizinle kaldığı anlamına gelir. Özel beyin fırtınası, kod yardımı ve belge soru-cevapları gibi işlemleri hiçbir şeyi çevrimiçi olarak göndermeden gerçekleştirebilirsiniz. Bu size uygun geliyorsa, sizi sıfırdan ilk komuta kadar götürelim.
Hangi Araçları Kullanıyoruz?
Şu anda en yeni başlayanlar için uygun seçenek Ollama, tek satırlık komutlarla geniş bir açık model kataloğunu indirip çalıştıran ücretsiz bir uygulamadır (artık Windows ve macOS masaüstü uygulaması da mevcuttur, böylece terminalde yaşamak zorunda kalmazsınız).
Daha görsel, hepsi bir arada bir deneyim tercih ediyorsanız, LM Studio (aynı zamanda ücretsiz) yerel modelleri keşfetmek, çalıştırmak ve yönetmek için başka bir harika seçenektir. Open WebUI, Ollama'nın üzerine yerleştirilebilen hafif, kendi kendine barındırılan bir sohbet arayüzüdür. Birini seçin veya karıştırıp eşleştirin.


İhtiyacınız Olanlar (Donanım ve İşletim Sistemi)
- İşletim sistemi: Windows 10/11, macOS veya Linux (aşağıda Windows örnekleri göstereceğiz).
- Bellek ve depolama: 16–32 GB RAM, 7–13B parametreli modeller için yeterlidir; daha fazla RAM, daha büyük bağlamlarda yardımcı olur. Modeller ve önbellekler için SSD'de onlarca GB boş alan bırakın.
- GPU (isteğe bağlı ancak yararlı): Modern bir GPU, işlemleri hızlandırır ve daha büyük modelleri çalıştırmanıza olanak tanır. Windows'ta Ollama, GPU hızlandırmayı destekler ve AMD için optimize edilmiş sürümler yayınlar.
- AMD entegre grafikler (APU'lar) hakkında not: Yeni Ryzen AI Max+ sistemleri, sistem belleğini "değişken grafik belleği" olarak paylaşabilir ve doğru yapılandırma ile iGPU'ya 96 GB'a kadar VRAM sunabilir. Bu, evdeki daha büyük modeller için kullanışlıdır.
Hızlı Başlangıç (Windows): İlk Komut İsteminize En Hızlı Yol
- Ollama'yı yükleyin
- Ollama'dan Windows yükleyicisini indirin veya Winget aracılığıyla yükleyin: "winget install --id Ollama.Ollama"
Yükleme tamamlandıktan sonra, hem Ollama uygulaması (GUI) hem de komut satırı aracına sahip olacaksınız.
- Başlat ve doğrula
- Ollama masaüstü uygulamasını açın ve istenirse oturum açın (yerel kullanım için bulut gerekmez).
- Veya CLI'yi doğrulayın: "ollama --version". (Bir sürüm numarası göreceksiniz.)
- Başlangıç modelini çekin
- Uygulamada bir modeli tarayın ve indirin. Veya terminalde: "ollama run llama3:8b" komutunu girin.
- "Bu, modeli indirecek ve sizi bir komut istemine yönlendirecektir — bir soru yazın ve devam edin. Ollama Kütüphanesi'nde birçok modeli (Gemma, Llama, Qwen, OLMo ve daha fazlası) inceleyebilirsiniz.
- (İsteğe bağlı) GPU hızlandırmayı etkinleştir
- Grafik sürücülerini güncel tutun. Ollama, AMD hızlandırmalı Windows sürümleri sunar ve AMD, Radeon'da LLM'ler için DirectML/ROCm yollarını belgeler. Ollama uygulamasında, GPU'nun algılandığını onaylayın (veya oluşturma sırasında Görev Yöneticisi'nde GPU kullanımını izleyin).
Hangi modeli önce denemelisiniz?
- "Küçük ve hızlı": gemma3:1b veya llama3:8b, hızlı yanıtlar ve düşük kaliteli donanımlar için idealdir.
- "Dengeli": 7B–13B modelleri (ör. olmo2:7b, llama3:8b instruct) genel kullanım için sağlamdır.
- "Daha büyük beyinler": 20B+ modeller (ör. gpt-oss:20b, daha büyük Llama varyantları) daha fazla RAM/VRAM ve sabır gerektirir, ancak daha zorlu görevlerde parlarlar. Bunların herhangi birini doğrudan uygulamada veya ollama run <model> komutuyla çalıştırabilirsiniz.
Yerel LLM'nizi optimize etmek için ipuçları
- Bağlam uzunluğu: Daha büyük her zaman daha iyi değildir. Çok büyük bağlamlar (örneğin, 32k-64k token) üretimi önemli ölçüde yavaşlatabilir. 4k–8k ile başlayın ve yalnızca gerektiğinde artırın.
- Kuantizasyon: Çoğu uygulama tarafından sağlanan modeller, daha büyük modelleri sınırlı VRAM'e sığdırmak için kullanışlı olacak şekilde önceden kuantize edilmiştir.
- Depolama: Modellerinizi SSD'de saklayın; HDD'ler yavaş çalışacaktır.
- Sürücüler: GPU sürücülerini ve uygulamayı düzenli olarak güncelleyin. Yerel yapay zeka hızla gelişiyor.
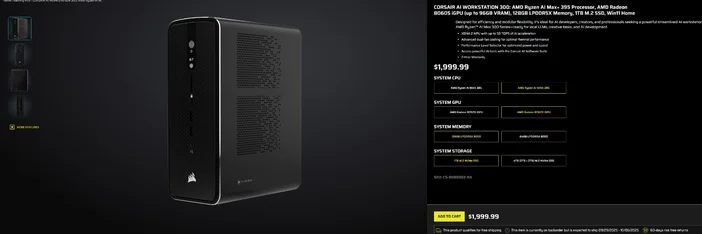
CORSAIR AI WORKSTATION 300'ü kullanma
Parça parça kurulumdan kaçınmak ve kutudan çıktığı anda yerel LLM'ler için hazır, kompakt ve sessiz bir masaüstü bilgisayar istiyorsanız, CORSAIR AI WORKSTATION 300 , yaratıcılar ve geliştiriciler için birçok özelliği bir arada sunar:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (96 GB VRAM'e kadar), XDNA 2 NPU 50 TOPS'a kadar
- Bellek ve Depolama: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB+2 TB)
- İşletim Sistemi: Windows 11 Home
- Tasarım: Çift fanlı soğutma ve Performans Seviyesi Seçici ile 4,4 L küçük form faktörlü kasa
Radeon iGPU'daki "96 GB'a kadar VRAM" özelliği, daha büyük yerel modeller ve daha uzun bağlamlar için GPU'ya büyük paylaşımlı bellek ayırabilen Windows araçlarıyla özellikle uyumludur. Kapasiteden ödün vermeden yerel AI geliştirmeye giden temiz ve kompakt bir yoldur.
Sıkça Sorulan Sorular
Yerel LLM'yi çalıştırmak için özel bir GPU'ya ihtiyacım var mı?
Hayır. Daha küçük modelleri yalnızca CPU bulunan sistemlerde çalıştırabilirsiniz, ancak yanıtlar daha yavaş olacaktır. Modern bir GPU veya büyük paylaşımlı belleğe sahip gelişmiş bir APU, hızı artırır ve model boyutunu yükseltmenizi sağlar.
Bu özel mi?
Evet. Ollama veya LM Studio gibi yerel araçlarla, komut istemleri ve veriler varsayılan olarak makinenizde kalır. (Eklediğiniz entegrasyonlar farklı davranabilir, her zaman ayarları kontrol edin.)
Modelleri nereden bulabilirim?
Ollama Kütüphanesi, popüler ve güncel seçenekleri (Llama, Gemma, Qwen, OLMo ve daha fazlası) listeler. Her model sayfasında boyutlar ve örnek komutlar gösterilir.
CORSAIR AI WORKSTATION 300 büyük modelleri işleyebilir mi?
Yerel LLM'ler için tasarlanmış olup, 128 GB bellek ve 96 GB VRAM'e erişebilen bir iGPU ile gelişmiş yerel iş yükleri ve uzun bağlamlar için mükemmel bir başlangıç alanı sunar, özellikle de AMD'nin Windows sürücüleri büyük tahsisler için desteği genişletirken. Gerçek verim, model boyutu, niceleme ve ayarlara bağlıdır.
MAKALEDEKI ÜRÜNLER
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.