Ein großes Sprachmodell (LLM) auf Ihrem eigenen PC zu betreiben, klingt einschüchternd, ist aber überraschend einfach. Ein „lokales LLM” bedeutet einfach, dass die KI auf Ihrer Hardware läuft – ohne Cloud, ohne Konto, und Ihre Daten bleiben bei Ihnen. Denken Sie an privates Brainstorming, Code-Hilfe und Dokument-Q&A, ohne dass Sie irgendetwas online senden müssen. Wenn das gut klingt, bringen wir Sie von Null auf die erste Eingabeaufforderung.
Welche Tools verwenden wir?
Die derzeit für Anfänger am besten geeignete Option ist Ollama, eine kostenlose App, die einen umfangreichen Katalog offener Modelle mit Einzeiler-Befehlen herunterlädt und ausführt (sie wird jetzt als Windows- und macOS-Desktop-App ausgeliefert, sodass Sie nicht in einem Terminal leben müssen).
Wenn Sie eine visuellere All-in-One-Erfahrung bevorzugen, LM Studio (ebenfalls kostenlos) eine weitere gute Wahl, um lokale Modelle zu entdecken, auszuführen und zu verwalten. Open WebUI ist eine leichtgewichtige, selbst gehostete Chat-Oberfläche, die auf Ollama aufgesetzt werden kann. Wählen Sie eine Option oder kombinieren Sie mehrere.


Was Sie benötigen (Hardware und Betriebssystem)
- Betriebssystem: Windows 10/11, macOS oder Linux (im Folgenden zeigen wir Beispiele für Windows).
- Arbeitsspeicher und Speicherplatz: 16–32 GB RAM sind für Modelle mit 7–13 Milliarden Parametern ausreichend; mehr RAM ist bei größeren Kontexten hilfreich. Halten Sie mehrere Dutzend GB auf einer SSD für Modelle und Caches frei.
- GPU (optional, aber hilfreich): Eine moderne GPU beschleunigt die Verarbeitung und ermöglicht die Ausführung größerer Modelle. Unter Windows unterstützt Ollama die GPU-Beschleunigung und veröffentlicht AMD-optimierte Builds.
- Hinweis zu integrierten AMD-Grafikkarten (APUs): Neue Ryzen AI Max+-Systeme können den Systemspeicher als „variablen Grafikspeicher“ gemeinsam nutzen und bei entsprechender Konfiguration bis zu 96 GB VRAM für die iGPU bereitstellen – nützlich für größere Modelle zu Hause.
Schnellstart (Windows): Der schnellste Weg zu Ihrer ersten Eingabeaufforderung
- Ollama installieren
- Laden Sie das Windows-Installationsprogramm von Ollama herunter oder installieren Sie es über Winget:„winget install --id Ollama.Ollama”
Nach der Installation stehen Ihnen sowohl die Ollama-App (GUI) als auch das Befehlszeilentool zur Verfügung.
- Starten und überprüfen
- Öffnen Sie die Ollama-Desktop-App und melden Sie sich an, wenn Sie dazu aufgefordert werden (für die lokale Nutzung ist keine Cloud erforderlich).
- Oder überprüfen Sie die CLI: „ollama --version“.(Sie sehen dann eine Versionsnummer.)
- Ein Einstiegsmodell ziehen
- In der App können Sie ein Modell suchen und herunterladen. Oder in einem Terminal: „ollama run llama3:8b
- Dadurchwird das Modell heruntergeladen und Sie gelangen zu einer Eingabeaufforderung – geben Sie eine Frage ein und los geht's. In der Ollama-Bibliothek können Sie viele Modelle (Gemma, Llama, Qwen, OLMo und mehr) durchsuchen.
- (Optional) GPU-Beschleunigung aktivieren
- Halten Sie Ihre Grafiktreiber auf dem neuesten Stand. Ollama bietet Windows-Builds mit AMD-Beschleunigung und AMD dokumentiert DirectML/ROCm-Pfade für LLMs auf Radeon. Vergewissern Sie sich in der Ollama-App, dass die GPU erkannt wird (oder beobachten Sie die GPU-Auslastung im Task-Manager während der Generierung).
Welches Modell sollten Sie zuerst ausprobieren?
- „Klein und flott“: gemma3:1b oder llama3:8b – gut für schnelle Antworten und Low-End-Hardware.
- „Ausgewogen“: Modelle 7B–13B (z. B. olmo2:7b, llama3:8b instruct) eignen sich gut für den allgemeinen Gebrauch.
- „Größere Gehirne“: Modelle mit mehr als 20 Milliarden Parametern (z. B. gpt-oss:20b, größere Llama-Varianten) benötigen mehr RAM/VRAM und Geduld, glänzen jedoch bei anspruchsvolleren Aufgaben. Sie können jedes dieser Modelle direkt in der App oder über ollama run <model> aufrufen.
Tipps zur Optimierung Ihres lokalen LLM
- Kontextlänge: Größer ist nicht immer besser. Riesige Kontexte (z. B. 32k-64k Token) können die Generierung erheblich verlangsamen. Beginnen Sie mit 4k–8k und erhöhen Sie die Länge nur bei Bedarf.
- Quantisierung: Die meisten von der App bereitgestellten Modelle sind bereits quantisiert, was praktisch ist, um größere Modelle in begrenzten VRAM unterzubringen.
- Speicherung: Speichern Sie Modelle auf einer SSD; HDDs sind zu langsam.
- Treiber: Aktualisieren Sie regelmäßig die GPU-Treiber und die App. Lokale KI entwickelt sich schnell weiter.
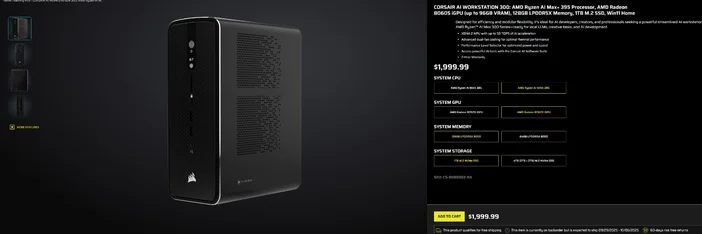
Verwendung der CORSAIR AI WORKSTATION 300
Wenn Sie lieber auf den schrittweisen Aufbau verzichten und einen kompakten, leisen Desktop-PC wünschen, der sofort für lokale LLMs einsatzbereit ist, dann ist die CORSAIR AI WORKSTATION 300 viele Anforderungen von Kreativen und Entwicklern erfüllt:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (bis zu 96 GB VRAM), XDNA 2 NPU mit bis zu 50 TOPS
- Speicher & Speicherplatz: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB + 2 TB)
- Betriebssystem: Windows 11 Home
- Design: 4,4-Liter-Gehäuse mit kleinem Formfaktor, Dual-Lüfter-Kühlung und Leistungsstufenwahlschalter
Die „bis zu 96 GB VRAM“ der Radeon iGPU lassen sich besonders gut mit Windows-Tools kombinieren, die der GPU großen gemeinsamen Speicher zuweisen können, was für größere lokale Modelle und längere Kontexte nützlich ist, wenn Sie diese benötigen. Dies ist ein sauberer, kompakter Weg in die lokale KI-Entwicklung, ohne Kompromisse bei der Kapazität eingehen zu müssen.
Häufig gestellte Fragen
Benötige ich eine dedizierte GPU, um ein lokales LLM auszuführen?
Nein. Sie können kleinere Modelle auf reinen CPU-Systemen ausführen, allerdings sind die Reaktionszeiten dann langsamer. Eine moderne GPU oder eine fortschrittliche APU mit großem gemeinsam genutztem Speicher verbessert die Geschwindigkeit und ermöglicht Ihnen eine Vergrößerung des Modells.
Ist das privat?
Ja. Mit lokalen Tools wie Ollama oder LM Studio bleiben Eingabeaufforderungen und Daten standardmäßig auf Ihrem Computer gespeichert. (Von Ihnen hinzugefügte Integrationen können sich anders verhalten. Überprüfen Sie daher immer die Einstellungen.)
Wo finde ich Modelle?
Die Ollama-Bibliothek listet beliebte, aktuelle Optionen auf (Llama, Gemma, Qwen, OLMo und mehr). Auf jeder Modellseite werden Größen und Beispielbefehle angezeigt.
Kann die CORSAIR AI WORKSTATION 300 große Modelle verarbeiten?
Es wurde für lokale LLMs entwickelt und verfügt über 128 GB Speicher und eine iGPU, die auf bis zu 96 GB VRAM zugreifen kann – ein hervorragender Spielraum für anspruchsvolle lokale Workloads und lange Kontexte, insbesondere da die Windows-Treiber von AMD die Unterstützung für große Zuweisungen erweitern. Der tatsächliche Durchsatz hängt von der Modellgröße, der Quantisierung und den Einstellungen ab.
PRODUKTE IM ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat the latest PC, tech, and gaming trends, our community is the place for you.